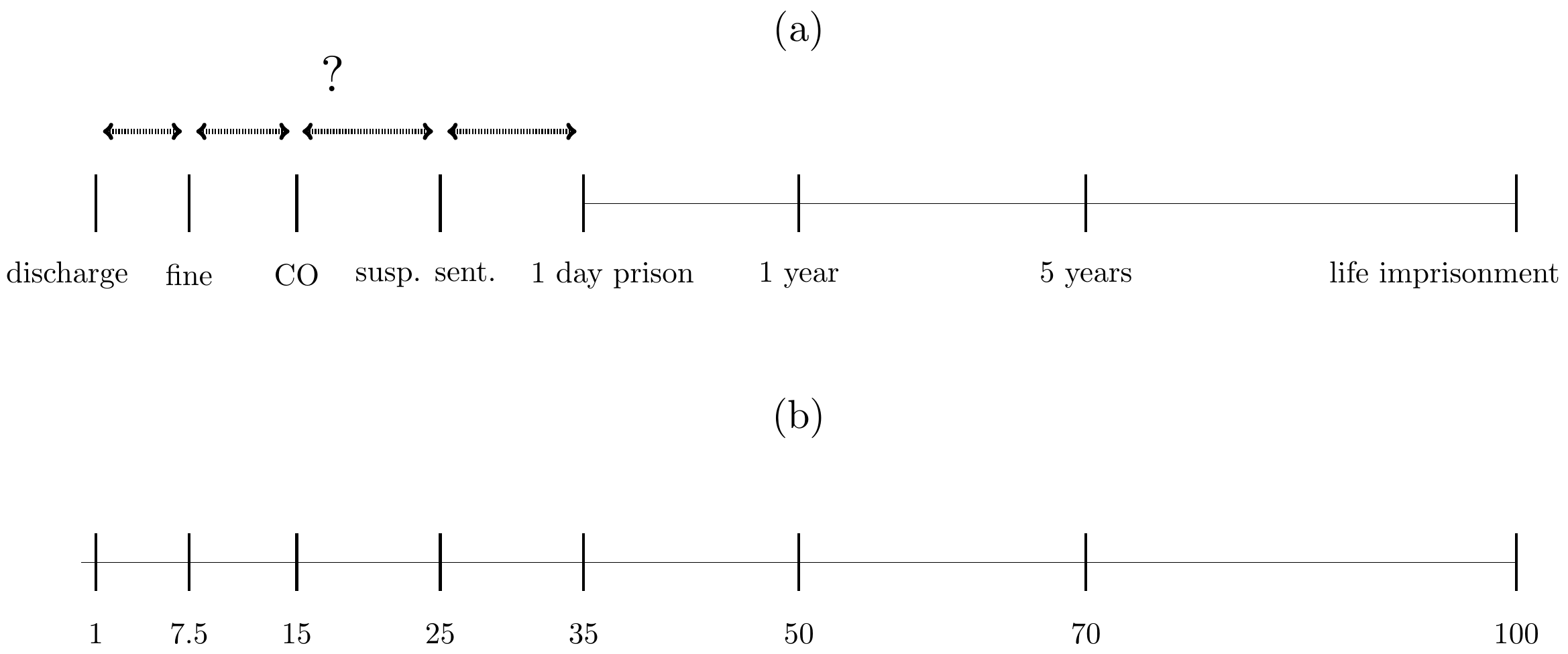
Operacionalizar la severidad
Diferentes tipos de sentencias basados en diferentes medidas
– multa (€), sanción comunitaria (condiciones), prisión (meses)
Escalas (subjetivas) de severidad (Pina-Sánchez & Gosling, 2020)
Sesgo de confusión
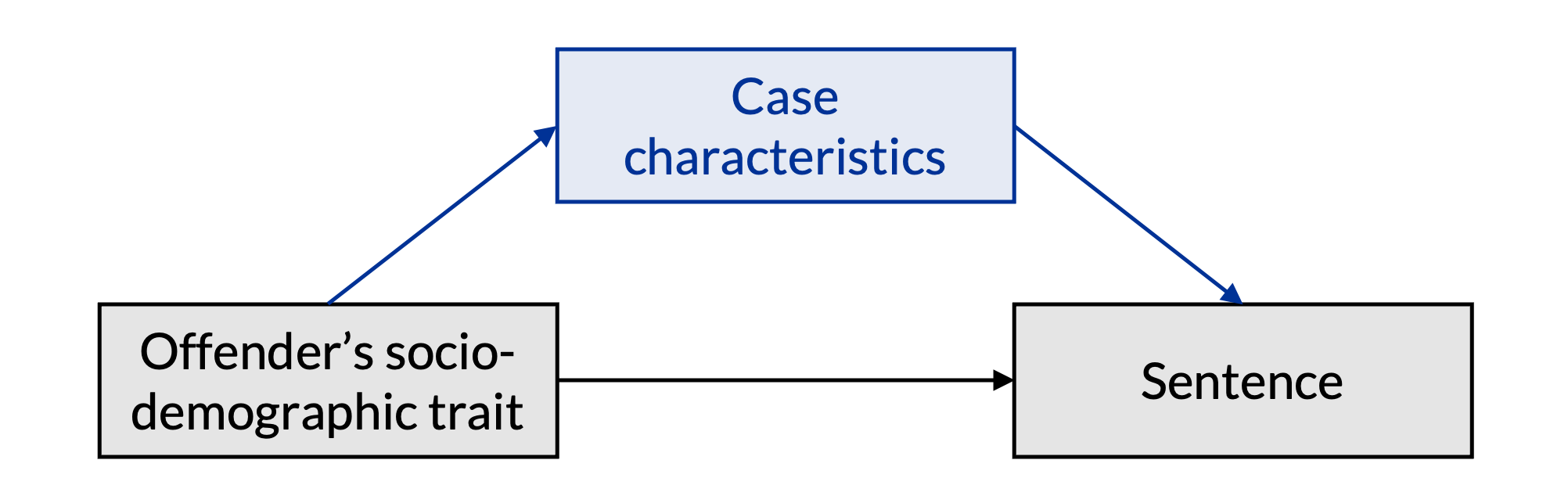
Necesitamos controlar por otras caractéristicas del caso
– métodos de emparejamiento
– métodos de regresión
Modelos de regresión
- Correlación entre dos variables controlando por otras variables
\[Y_i=\beta_0+\beta_1X_{1,i}+\beta_{k}X_{k,i}+\epsilon_i\]
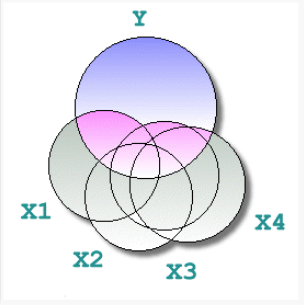
Aplicar controles de manera crítica

No es buena idea controlar por todas las caráctesticas del caso
No podemos estimar con exactitud el nivel de discriminación (Pina-Sánchez et al., 2025)